Goal: Hone skill at using Lenz’s Law
Source: 283-CTQsas36
Consider the four situations below in which a wire loop lies in the
plane of a long wire. In which case(s) is the induced current in the
loop in the counterclockwise direction? [Note: if no velocity is
indicated, the loop is stationary.]
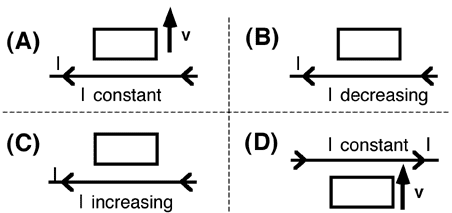
- A only
- B only
- C only
- D only
- A and B
- C and D
- All cases.
- None of the above.
Commentary:
Answer
recognizing that the induced current is in a direction that causes the
field of the induced current to compensate for the change in flux. Even
when they nominally understand that, they have trouble reliably applying
the right hand rule.